
Introduction
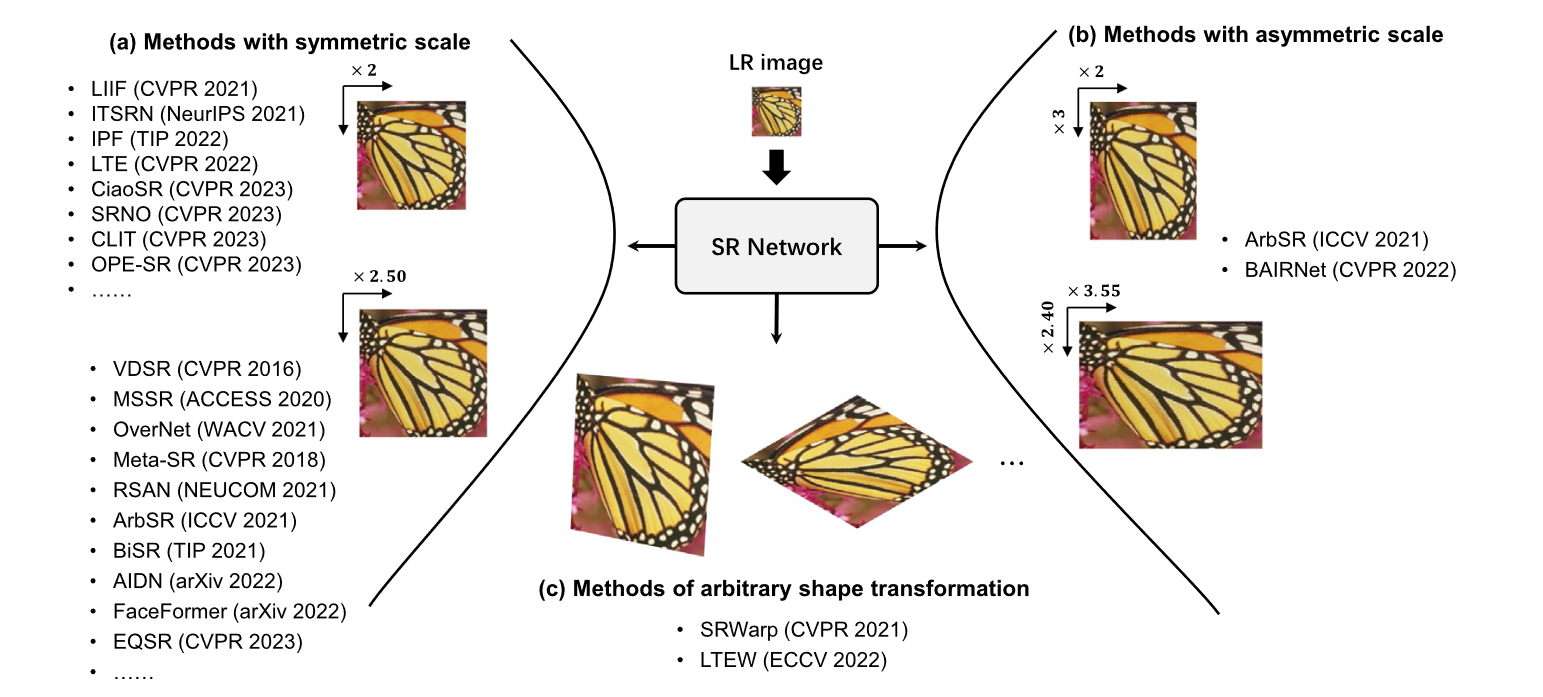
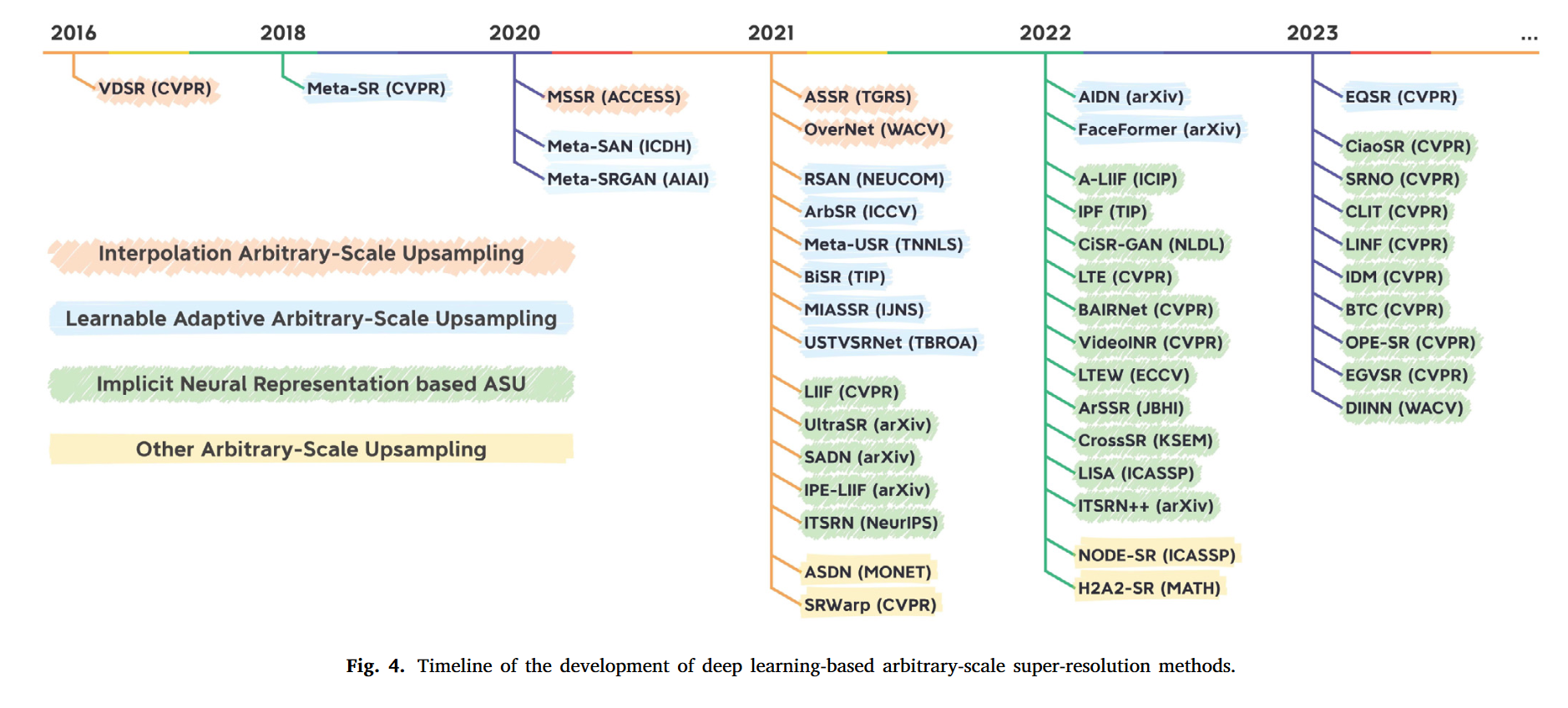
过去的固定尺度超分存在许多缺点,如多尺度需要多个权重,对存储和计算又较高要求。任意尺度超分可以解决这些问题。本文立足任意尺度超分,提出了一种分类方法。首先按照超分尺度分,可以分成对称尺度(长宽一致)、非对称(长宽不一致)尺度超分和任意形状超分。对称尺度又可以分为整数尺寸和非整数尺寸。按照插值方法来分,又可以分为:插值超分和可学习自适应超分。
Preliminaries
Definition
HR图到LR图的退化过程被定义为:
\[I_{LR} = \mathcal{D}(I_{HR};\delta)\]其中$\mathcal{D}$是一个以$\delta$为参数的退化模型。超分任务是通过恢复$I_{LR}$来逼近原始的$I_{HR}$。这个恢复过程可以被概括为: $I_{SR}=\mathcal{S}(I_{LR};\theta)$ 其中$\mathcal{S}$是以$\theta$为参数的模型。 常见的用Bicubic核进行下采样的退化方式可以描述为:
\[I_{LR}=D(I_{HR};\delta)=I_{HR}\downarrow_{s}^{bic},\]其中$\downarrow_{s}^{bic}$表示下采样,$s$是尺寸。另一种退化方式是用高斯模糊核$k_g$外加高斯噪声$\mathbf{n}$:
\[I_{LR}=D(I_{HR};\delta)=(I_{HR}\otimes k_g)\downarrow_s^{bic}+n,\]基于上述定义,我们可以将超分描述为:
\[\hat{\theta}=\arg\min\mathcal{L}(I_{SR},I_{HR}),\]Datasets
基于Bicubic 下采样的数据集被记作BI,基于高斯核的被记作BD。
Metrics
PSNR: Peak signal-to-noise ratio
老熟人:
\[\mathrm{MSE}=\frac{1}{HW}\sum_{i=1}^{H}\sum_{j=1}^{W}\left(I_{HR}(i,j)-I_{SR}(i,j)\right)^{2},\\ \mathbf{PSNR}=10\log_{10}\left(\frac{L^{2 }} {\mathbf{MSE }} \right).\]$L$是指数据范围,对于8bit图像而言就是255。对于PSNR我有个疑惑:假设源图像是$I_{HR}$,量化过后是$\hat{I}_{HR}$。量化的过程相当于是加上一个均匀分布的噪声$\textbf{u}$,即$\hat{I}_{HR}=I_{HR}+\textbf{u}$。而对于超分图像$I_{SR}$,可以看做是$I$进行一个低通滤波,即$I_{SR}=I*LPF$,PSNR的MSE项严格来说应该写作
\[\mathrm{MSE}=\frac{1}{HW}\sum_{i=1}^{H}\sum_{j=1}^{W}\left(I_{HR}(i,j)-I_{SR}(i,j)\right)^{2},\]然而现在的PNSR的MSE项实际上是
\[\mathrm{MSE}=\frac{1}{HW}\sum_{i=1}^{H}\sum_{j=1}^{W}\left(\hat{I}_{HR}(i,j)-I_{SR}(i,j)\right)^{2}\]SSIM: Structural similarity
$\sigma_{hr},\sigma_{sr}$分别是他们的标准差,$\sigma_{hrsr}$是协方差。
\[\begin{aligned} &l\left(I_{SR},I_{HR}\right)=\frac{2\mu_{sr}\mu_{hr}+C_{1 }} {\mu_{sr}^{2}+\mu_{hr}^{2}+C_{1 }} , \\ &c\left(I_{SR},I_{HR}\right)=\frac{2\sigma_{sr}\sigma_{hr}+C_{2 }} {\sigma_{sr}^{2}+\sigma_{hr}^{2}+C_{2 }} , \\ &s\left(I_{SR},I_{HR}\right)=\frac{2\sigma_{hrsr}+C_{3 }} {\sigma_{sr}\sigma_{hr}+C_{3 }} , \\ &\mathrm{SSIM}=\left[l\left(I_{SR},I_{HR}\right)\right]^{\alpha}\left[c\left(I_{SR},I_{HR}\right)\right]^{\beta}\left[s\left(I_{SR},I_{HR}\right)\right]^{\gamma}, \end{aligned}\]其中$l(I_{SR},I_{HR}),c(I_{SR},I_{HR}),s(I_{SR},I_{HR})$分别表示亮度,对比度,结构。常见参数设置为$\alpha=\beta=\gamma=1$ and $C_{3}=C_{2}/2.$
LPIPS: Learned perceptual image patch similarity
LPIPS 根据原始HR图像和SR图像之间的感知相似性来衡量它们之间的差异。LPIPS 使用深度神经网络从图像块中提取特征,然后计算这些特征之间的距离,以测量两幅图像之间的感知相似度。 一般来说,LPIPS比PSNR和SSIM更符合人类对图像质量的感知,LPIPS得分较低意味着两幅图像更相似。
Loss function
一般来说,任意尺度的超分辨率模型都是使用多尺度数据对进行训练的,例如从均匀分布$U(a,b)$中采样的尺度$s$,其中$a$和$b$分别是训练尺度的上界和下界。
Pixel Loss
Pixel Loss 包括L1、L2和Charbonnier Loss.Charbonnier 是一种关于平均绝对误差的改进。
\[\mathcal{L}_{L1}(I_{SR},I_{HR})=\mathbf{E}_{s\sim U(a,b),I_{HR }} \left\|I_{SR}^{(s)}-I_{HR}\right\|_{1},\] \[\begin{aligned}&\mathcal{L}_{L2}(I_{SR},I_{HR})=\mathbf{E}_{s\sim U(a,b),I_{HR }} (I_{SR}^{(s)}-I_{HR})^{2},\\\\&\mathcal{L}_{cha}(I_{SR},I_{HR})=\mathbf{E}_{s\sim U(a,b),I_{HR }} \sqrt{(I_{SR}^{(s)}-I_{HR})^{2}+\varepsilon^{2 }} ,\end{aligned}\]Perceptual Loss
感知损失也称为内容损失(Content Loss),通过使用训练好的分类网络来评估图像之间的语义差异,如VGG和ResNet。与像素损失相比,感知损失追求的是高层次感知质量的一致性,而不是像素级别的一致性。因此,一些任意尺度的超分辨率模型使用感知损失来避免产生过度平滑的结果。
\[\mathcal{L}_{perc}(I_{SR},I_{HR};\Gamma,l)=\mathbf{E}_{s\sim U(a,b).I_{HR }} \sqrt{(\Gamma^{(l)}(I_{SR}^{(s)})-\Gamma^{(l)}(I_{HR}))^{2 }} ,\]其中$\Gamma$是一个分类器网络,$\Gamma^{(l)}$是网络$l$层feature。
Adversarial Loss
对抗Loss被定义为:
\[\begin{array}{l}{ {\mathcal{L}_{adv_{g }} (I_{SR};D)=-logD(I_{SR}), }} \\ {{ \mathcal{L}_{adv_{d }} (I_{SR},\hat{I}_{HR};D)=-logD(\hat{I}_{HR})-log(1-D(I_{SR})), }} \end{array}\]其中$\mathcal{D}$表示鉴别器生成的二值类别。部分工作指出log换成平方项可以增加稳定性和提升效果。即:
\[\begin{array}{l}{ \mathcal{L}_{adv_{g_{-}Ise }} (I_{SR};D)=(D(I_{SR})-1)^{2},}\\ {\mathcal{L}_{adv_{d\_lse }} (I_{SR},\hat{I}_{HR};D)=(D(\hat{I}_{HR}))^{2}-(D(I_{SR})-1)^{2}.} \end{array}\]Multi-scale Loss
考虑多个尺度,获得$I_{SR}^{(s)}=Bicubic_{\downarrow}(I_{SR},s)$。多尺度Loss被定义为
\[\mathcal{L}_{ms}(I_{SR}^{(s)},I_{HR})=\left\|I_{SR}^{(s)}-\text{Bicubic}_{\downarrow}(I_{HR},s)\right\|_1.\]多尺度Loss能提供额外的监督,能提升网络的跨尺度泛化能力。有个疑惑是:这个Loss应该是多个$s$值的情况下获得的Loss的叠加,为什么这里没有求和。
Other losses
任意尺度超分Loss很多,有基于difussion模型的loss,negative loglikelihood loss,flow model joint loss等。
基于尺度分类的超分
固定整数尺度超分
固定整数尺度超分把不同尺度的超分任务看做不同的任务分开来看。他们通过亚像素卷积(卷积+Pixel Shuffle)或者反卷积来实现。典型网络有ESPCN, RED-Net, EDSR, DBPN, RDN, RCAN, and SwinIR。
Multi-Scale Super-Resolution network (MDSR)一次性可以超分三个尺度。在网络的开始用$5\times 5$的卷积来获得一个大的感受野。
有许多工作做了X8,X16,X32倍等的大尺度超分。但是这些方法都只能处理一个尺度。
LIIF 将神经网络隐式表示引入了超分,其建立了一个坐标到RGB的映射,实现任意尺度的超分。
UltraSR在LIIF的基础上增加了位置编码以增强高频材质的超分。
LTE增加了对自然图像的频域估计器,使其能够捕获高频信息。
IPF为接近模糊边缘的像素分配偏移量,使其更接近真实的锐利边缘
CiSR-GAN 使用对抗loss来提升感受指标
非整数尺度超分
2016年提出的very deep convolutional network (VDSR)可以实现如1.5倍这样的非整数倍超分。作者直接在卷积层前面加了插值再过神经网络来达到目的。
Multiplescaling-based SR (MSSR)根据指定的尺度选择一个最优的整数尺度因子,然后最后使用插值将图像缩放到目标尺寸。
Super-resolution with overscaling network (OverNet)生成了过尺度feature然后通过插值实现任意尺度超分。
ASDN采用了拉普拉斯金字塔方法,在该方法中,图像是由预先计算的拉普拉斯金字塔层次的稀疏集合插值构造的
Arbitrary Scale SR (ASSR) 用亚像素卷积和Bicubic插值实现卫星图像视频超分
Meta-SR 收到元学习的启发,提出了magnificationarbitrary Network (called Meta-SR)。首次实现了单模型任意尺度超分。在此之上,Meta-SAN把Meta-SR里面地特征提取部分换成了二阶注意力网络。Meta-SRGAN实现用任意尺度超分方法做MRI图像超分。Medical image arbitrary scale super-resolution(MIASSR)在Meta-SRGAN基础上提高了保真度。
非对称尺度超分
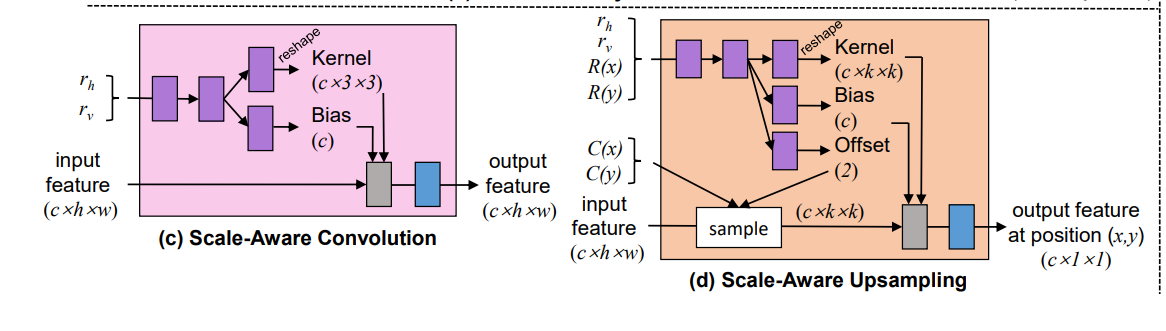
非对称尺度超分就是指长宽超分比例不一样。Scale-arbitrary super-resolution (ArbSR)提出了一种plug and play的模块实现任意尺度超分。ArbSR使用了动态卷积。其参数由长宽上的超分因子参与生成。ArbSR还使用了scale-aware的上采样模块。下图为ArbSR的核心部分。
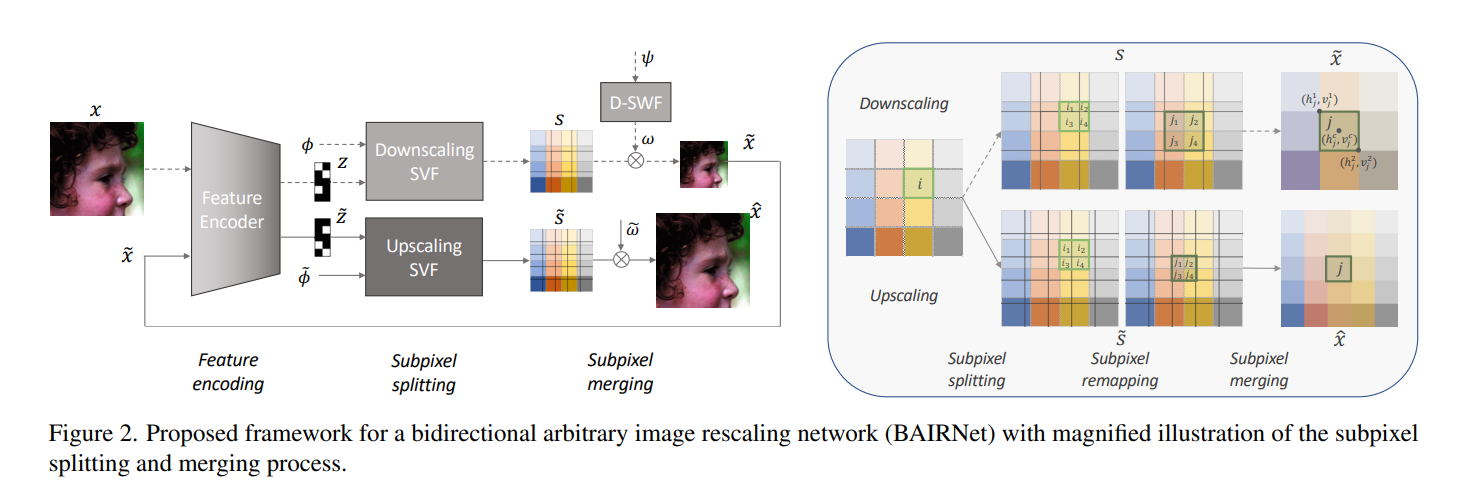
Bidirectional Arbitrary Image Rescaling Network (BAIRNet)能够实现任意尺度上采样和下采样。在上采样时有较好表现。下采样时能保持图片的感受质量。
任意尺度变换超分
就是超分出来的图片不一定是方的,可以由一定的形变。
《SRWarp: Generalized image super-resolution under arbitrary transformation》的作者将该任务解释为空间变化的超分任务然后提出了SRWrap方法。SRWrap并不是基于规则的矩形网格的,而是基于不规则网格采样的,所以能实现不规则变换。(个人觉得说白了就是获得不规则输入图像的仿射变换已知,然后作为信息去学)
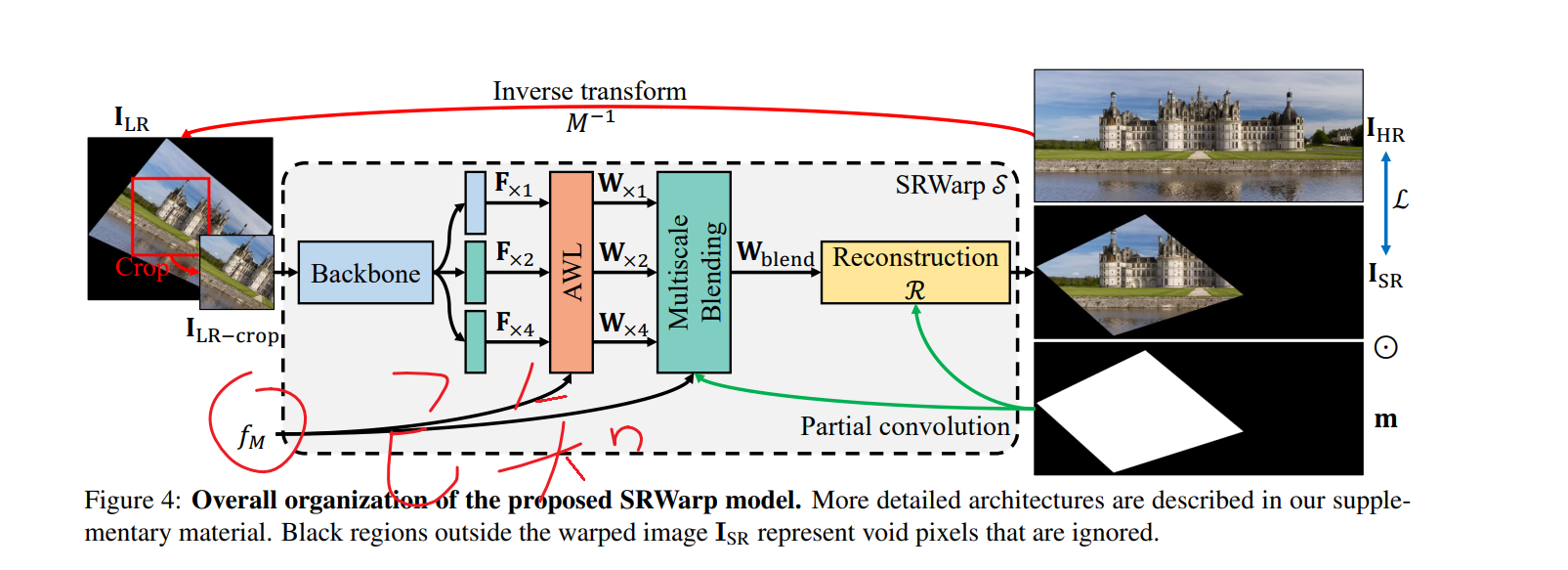
为了解决隐式神经表示在恢复高频信息方面的局限性,提出了一种用于图像变形的局部隐式傅里叶表示和局部纹理估计器(LTEW)。
上述两种方法都能用一个网络实现不同尺度的超分而不用插值。
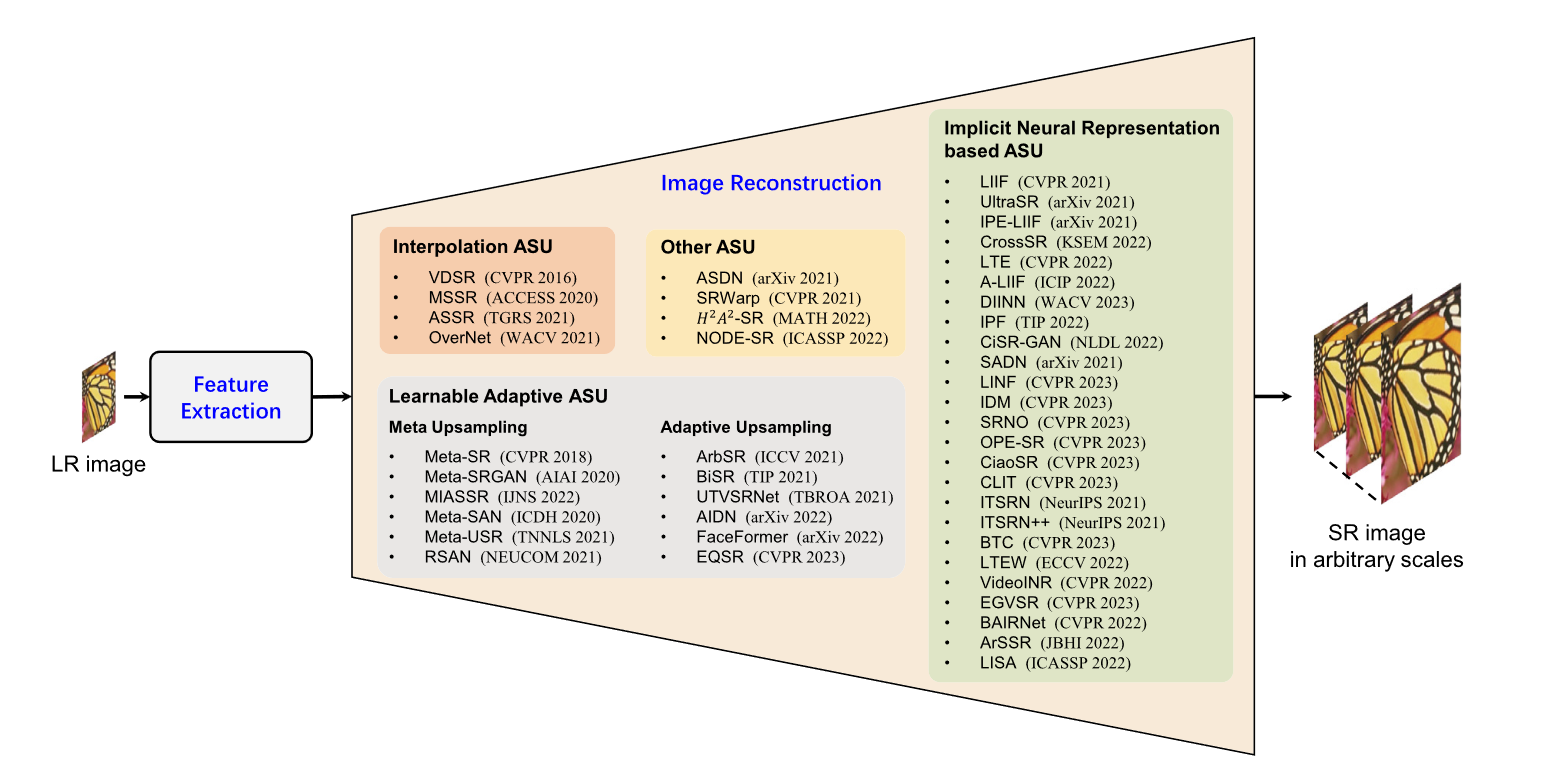
基于上采样方法的分类
超分可以分成两个步骤:feature extraction 和 image recovery。Feature extraction 的关键在于提取高频细节信息。按照 image recovery 的方式来分,可以分为四类:interpolation arbitrary-scale upsampling (IASU);implicit neural representation based arbitrary-scale upsampling (INRASU);learnable adaptive arbitrary-scale upsampling (LAASU);other arbitrary-scale upsampling (OASU)
 代表方法有:
IASU:VSDR、MetaSR
INRASU:LIIF
LAASU: ArbSR
代表方法有:
IASU:VSDR、MetaSR
INRASU:LIIF
LAASU: ArbSR
Interpolation Arbitrary-Scale Upsampling (IASU)
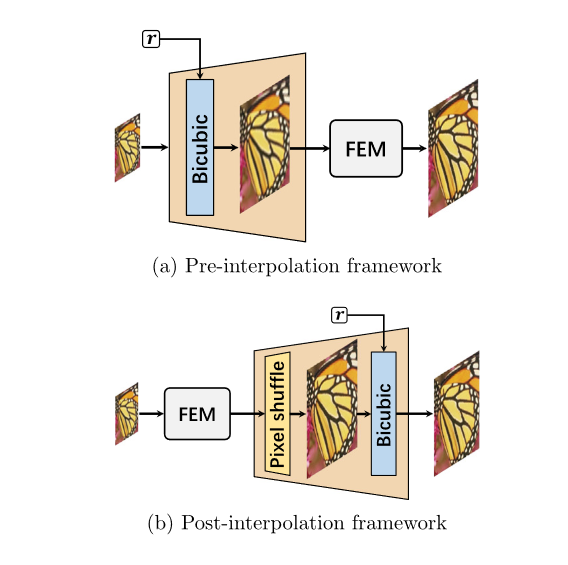
这类网络大致可以分为Pre-interpolation和Post-interpolation。古早的任意尺度超分多采取Pre-interpolation结构。好出是降低学习难度,坏处是在大尺度图上卷积计算开销大。后来Multi-Scale Super-Resolution method (MSSR) 使用了Post-interpolation方法。对于非整数超分,MSSR计算出最优的超分比例,然后选择对应的模型,最后将超分结果用Bicubic下采样到目标尺寸。
Arbitrary video satellite images(ASSR)使用feature extraction模块提取特征,然后上采样模块用亚像素卷积到目标尺寸,最后Bicubic插值到目标尺寸。
super-resolution network with overscaling network (OverNet) 轻量级网络提出多尺度loss来实现跨尺度泛化。
IASU是最简单的任意尺度超分方法,但是有很明显的缺点:会引入噪声和模糊,尺寸较大时推理时间变长。
Learnable adaptive arbitrary-scale upsampling(LAASU)
自适应任意尺度上采样的核心就是从训练集中学到上采样核参数。目前主流的思想有两种:基于元学习和基于动态卷积。
元学习
Meta-SR首次利用了元学习来动态预测不同尺度的核权重。Meta-SR包含了Feature Extraction Module(FEM)和meta-upscale模块。meta-upscale模块可以用来替代亚像素卷积。动态生成$HW$套卷积核,每套卷积核只负责生成SR图的一个像素。
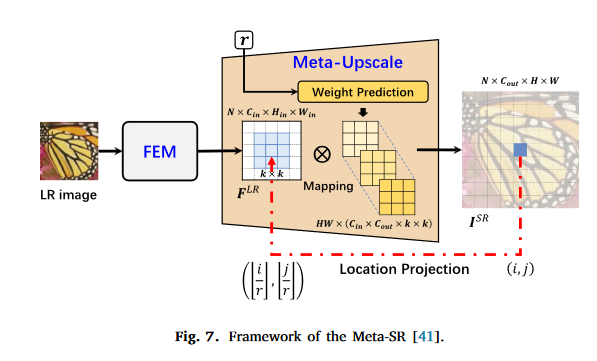
Meta-SR有很多后续工作: Meta-SRGAN:融合SARGAN,用于超分MRI图像。 MIASSR:用EDSR作为backbone和adversarial loss来提升保真度,用于MRI和CT超分。 Meta-SAN:引入二阶注意力,在natural image上表现良好。 Meta-USR:联合模型,综合考虑模糊、噪声和超分三个任务。
缺陷:在未训练的尺度上超分效果不好
自适应上采样
核心方法是动态卷积。Scale-arbitrary super-resolution (ArbSR)首次提出了一种叫做SAFAB的plug-in的模块来实现任意尺度超分。作者借鉴了动态卷积(conditional convolution)的想法,并且拓展了pixel shuffle层来实现任意尺度超分。对于HR空间中的$(x,y)$坐标,计算LR空间中的对应坐标$(L(x),L(y))$和相对距离$(R(x),R(y))$。然后尺度因子$r_h,r_v$和相对位置送进MLP层来生成偏移$(\delta_x,\delta_y)$以及$k\times k$的卷积核。最后LR空间中以$(L(x)+\delta_x,L(y)+\delta_y)$为中心的的$k\tiems k$的领域被送进卷积核来生成HR空间中$(x,y)$的像素。
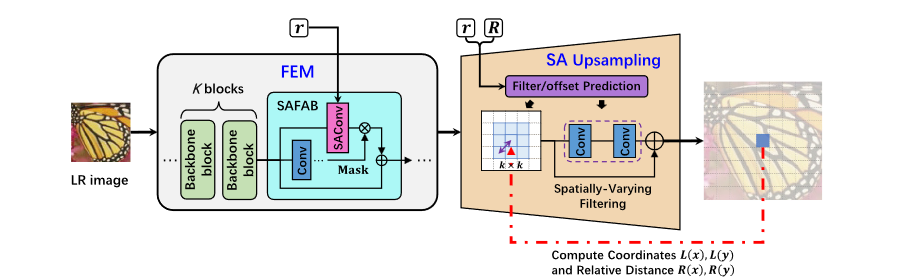
SAFAB受到了不同尺度超分网络的启发:网络中不同区域对尺度的变化敏感程度是不一样的。所以文章还提出来scale-aware convolution。它根据不同超分尺度来动态生成卷积核。对于不同的尺度,特征图的区域既有相似之处,也有不同之处。 SAFAB 旨在适应这种变化。 它使用 SAConv 使输入特征适应相应的 SR 尺度。同时,它利用卷积来学习一个mask,并使用该mask来执行适应特征与原始输入特征的混合。 上述特征修改模块和尺度感知上采样模块都可以通过简单的变换轻松地将任何主流ISR网络转变为任意尺度的SR网络。
改进方法有如下这些: Bilateral Upsampling Network (BiSR):结合位置和内容信息,引入图像内容信息来自适应学习双边上采样滤波器的权重。双边上采样滤波器是空间上采样滤波器和范围上采样滤波器的组合,可以针对不同的尺度因子和不同的像素值自适应地学习不同的滤波器权重。提出了通道维度特征的上采样,降低了生成双向上采样核的生成计算复杂度的同时保留结构信息。
Scale-arbitrary reversible image transformation framework (AIDN):一种用于图像压缩的网络,采用encoder-decoder结构,将图像压缩到指定大小,然后能任意尺度超分。该方法核心是ArbSR提出的动态卷积,根据缩放因子和图像内容缺点核和采样位置。
FaceFormer:blind face restoration。包含facial feature upsampling(FFUP)和facial feature embedding(FFE)。FFUP实现上采样,FFE用生成模型(如GAN)生成脸部细节。
在任意尺度的图像超分辨率任务中,尺度等变性处理块的能力起着至关重要的作用,即根据输入尺度的变化自适应地处理feature。Scale-equivalent super-resolution network (EQSR) 在Transformer式框架下提出了两个尺度等变模块:Adaptive Feature Extractor (AFE)和learnable Neural Kriging upsampling operator。AFE在频率扩展编码中注入显式的尺度信息。上采样模块算子编码距离和feature相似性。(没看懂这段在说啥)
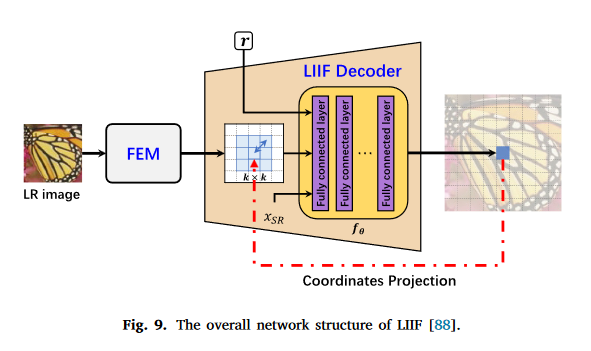
Implicit neural representation based arbitrary-scale upsampling
老熟人,用编码器把图片编码,然后用全连接实现坐标到RGB像素的映射。
从频域角度来看待
《On the spectral bias of neural networks》指出全连接层倾向学习低频信息,不能很好地拟合高频细节。基于这个问题,有如下改进:
UltraSR:基于LIIF设计了空间编码方式,把2D空间输入拓展到48D编码。
Integrated positional encoding-LIIF (IPE-LIIF):把传统位置编码拓展到二维
CrossSR:提出Cross Transformer增强跨尺度特性,用动态位置编码进一步提升表现
LTE:一种自然的图像主频估计器,它建立在隐函数在利用图像主频时优先学习图像纹理的假设之上。
Adaptive LIIF(ALIIF):LIIF所有像素都共用同样的MLP参数,ALIIF设计了一个拓展网络,把这个MLP参数设计成自适应地。
DIINN:设计了一个dual interactive 网络来实现内容和位置(调制分支、合成分支)的解耦(不知道解耦这里作何解释)。
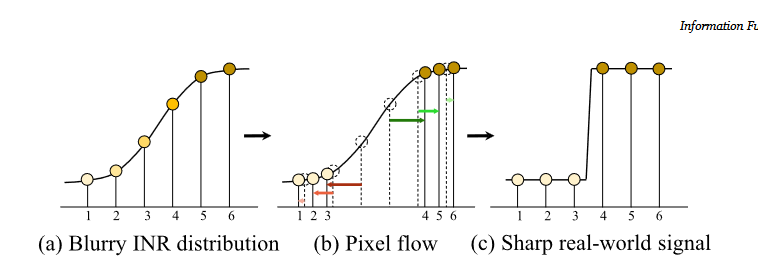
Implicit pixel flow (IPF):模拟INR模糊分布分布于锐利的真实分布之间的依赖关系。作者指出:模糊的边界可以简单的通过把周围像素squeeze得更紧就可以变得锐利。IPF旨在通过在最近邻位置用一个更合适的值替换每个像素的原始RGB值来恢复锐利的边缘。
continuous ISR method with implicit neural networks and generative adversarial networks (CiSR-GAN): 用生成模型实现photo-realistic,以解决LIIF模糊的问题。
Scale-aware dynamic network (SADN):相比于LIIF仅用一个latent space的做法,SADN用了多个尺度的latent space来预测像素。用了不同尺度因子动态生成卷积核。
The local implicit normalizing flow (LINF):为了解决INR忽略了超分是一个不适定问题,提出了local implicit normalizing flow.它对不同缩放因子下的纹理细节分布进行建模,以生成具有丰富纹理细节的逼真 SR 图像。
IDM: 集成了隐式神经表示和去噪扩散模型。
SRNO:将LR - HR图像对视为用不同网格尺寸近似的连续函数,并学习相应函数空间之间的映射。提升效果,降低运行时间
反转一致性
基于隐式表示的超分方法对encoder生成的latent code依赖很严重,因为MLP和encoder是一起训练的。如果将encoder生成的latent code flip一下,就会出现模糊。这种现象被称作反转一致性退化(decline of flipping consistency)。

为了解决这个问题,OPESR提出了正交位置编码。它提出的OPE-Upscale可以用于替代INR中的上采样模块,并且不需要训练参数。他可以直接以线性组合的方式进行,以连续的方式重建图像。
解决local ensemble问题
基于隐式神经表示的上采样需要集成LR特征域中的局部特征来预测SR图像中任意查询坐标下的新像素。他的局部集成没有可学习的参数,忽略了视觉特征的相似性。而且,它的感受野有限,无法集成图像的全局信息。通常,局部集成基于坐标线性地计算特征,这与真实的图像分布不同。
为了解决这个问题,continuous implicit attention-in-attention network (called CiaoSR)提出了一种隐式注意力网络来学习这个local ensemble编码。其他方法都直接借鉴LIIF的使用MLP进行坐标到RGB的映射,忽略了feature similarity。CiaoSR同时从前面学习soft weight、visual feature 和坐标。CiaoSR是一种plug and play的方法,可以灵活插入其他网络。
CLIT把注意力和频率编码集成到一个local implicit image function,并且采用了跨尺度局部注意力来聚合局部feature。同时它采用了multi-scale feature cascades来增强表现力。训练过程中,CLIT采用了逐步增加上采样倍数的方法。
其他任务超分
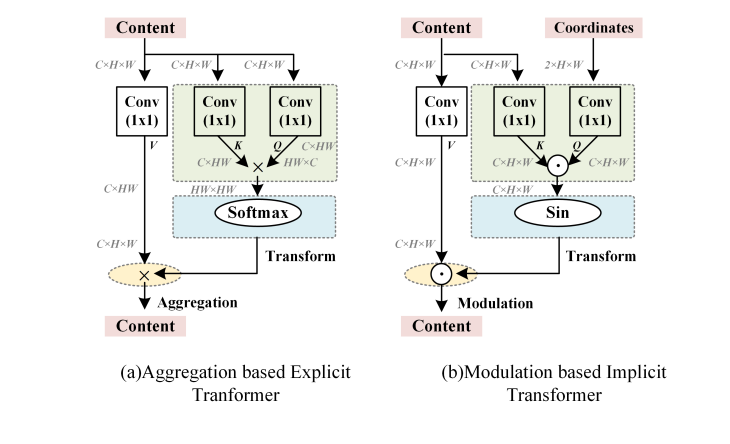
Implicit Transformer Super-Resolution Network (ITSRN)是一个用于屏幕内容(Screen Content Image)超分的网络。采用坐标与像素一一对应的模式,即transformer的q,k都是坐标。这样的方法更适合屏幕内容这样有薄而尖锐的边缘的图像。
ITSRN++:采用了modulation-base transformer。所谓的modulation transformer,就是平台transformer的softmax换成sin
BTC是使用B-splines的inr模型。BTC提取B样条的缩放、平移和平滑参数,然后MLP利用估计的B样条恢复SR图像。
LTEW:用于处理image wrapping任务的网络。LTEW利用了坐标变换的雅克比矩阵和从输入图像中估计的傅里叶特征。
VideoINR:不太了解,很多词不清楚含义,略过
BAIRNet: 将任意尺度超分引入image rescaling任务(同时包括图像放大和缩小)。BAIRNet将降尺度和升尺度建模为等价的亚像素差分分裂和合并过程,并采用循环学习策略。BAIRNet引入亚像素权重函数和亚像素权重进行亚像素分割(升尺度)和合并( Downscale ),与LIIF中类似。
ArSSR将INR引入MRI图像超分。LISTA将连续表示引入声音超分,这使得低分辨率音频信号中缺失的高分辨率成分的预测成为可能(感觉声音超分就是一个完全无意义的任务,因为经典方法已经理论上完美了)
总结
INR在训练尺度外的超分效果好,近年来是一个研究热点,近年来的一些方法也解决了LIIF的一些问题,如频谱角度看待,翻转一致性,local ensemble。然而,大多数基于LIIF的方法使用现有的骨架进行特征提取,而尺度信息只用于上采样而不在特征提取中使用。因此,针对不同规模的SR任务提取相似的特征。这可能会阻碍性能的进一步提升。总之,LIIF在二维离散信号和连续表示之间架起了一座桥梁。值得进一步研究。
其他任意尺度超分方法
上述的超分网络存在不可忽略的问题,例如整数尺度上超分比不过固定尺度超分网络。没有使用插值或者任意尺度上采样的方法在这个部分中介绍。
A high-frequency attention network ($𝐻^2𝐴^2-SR$):不修改现有整数倍数超分网络结构,但是在离散余弦变换空间下去实现插值以达到目标尺度。同时,为了解决DCT频谱扩展导致的高频信息缺失问题,H2A2-SR引入了高频注意力网络进行尺度的任意提升来恢复高频信息。
Neural ordinary differential equation (NODE-SR): 文章提出了一种Neural ordinary differential equation, 利用ODE进行超分。给定LR图像作为初始条件,能够使用传统restoration网络和ODE solver来求解提出的ODE以实现超分。这个方法只需要在测试室改变初始条件,天然就能进行超分。
ASDN:基于拉普拉斯金字塔。它这说明不同尺度下的图像块具有相似性,图像的边缘具有可伸缩的趋势,使得不同尺度下的图像具有相似的边缘信息,主要表现为高频信息。它在一组稀疏的训练尺度之间进行插值,以实现尺度任意的ISR,而一个大的上采样尺度因子可以表示为小范围尺度因子的整数次幂,从而可以递归地实现尺度任意的上采样。
SRWarp:第一个实现任意形状变换的网络,作者称其为非平面超分。
实验结果
太长了,可以参考论文。这里只放部分DIV2K数据集的结果
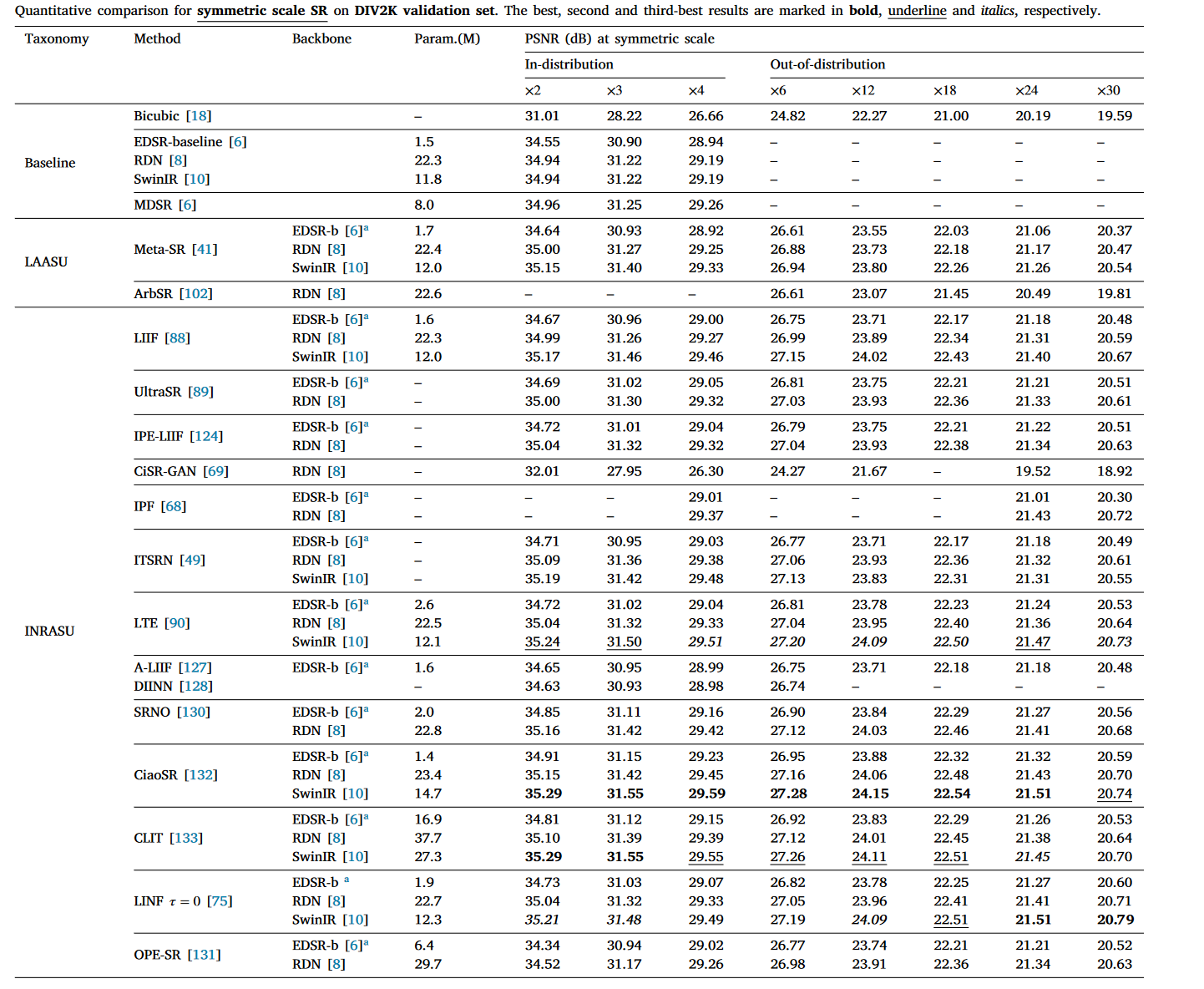
Symmetric integer scale:
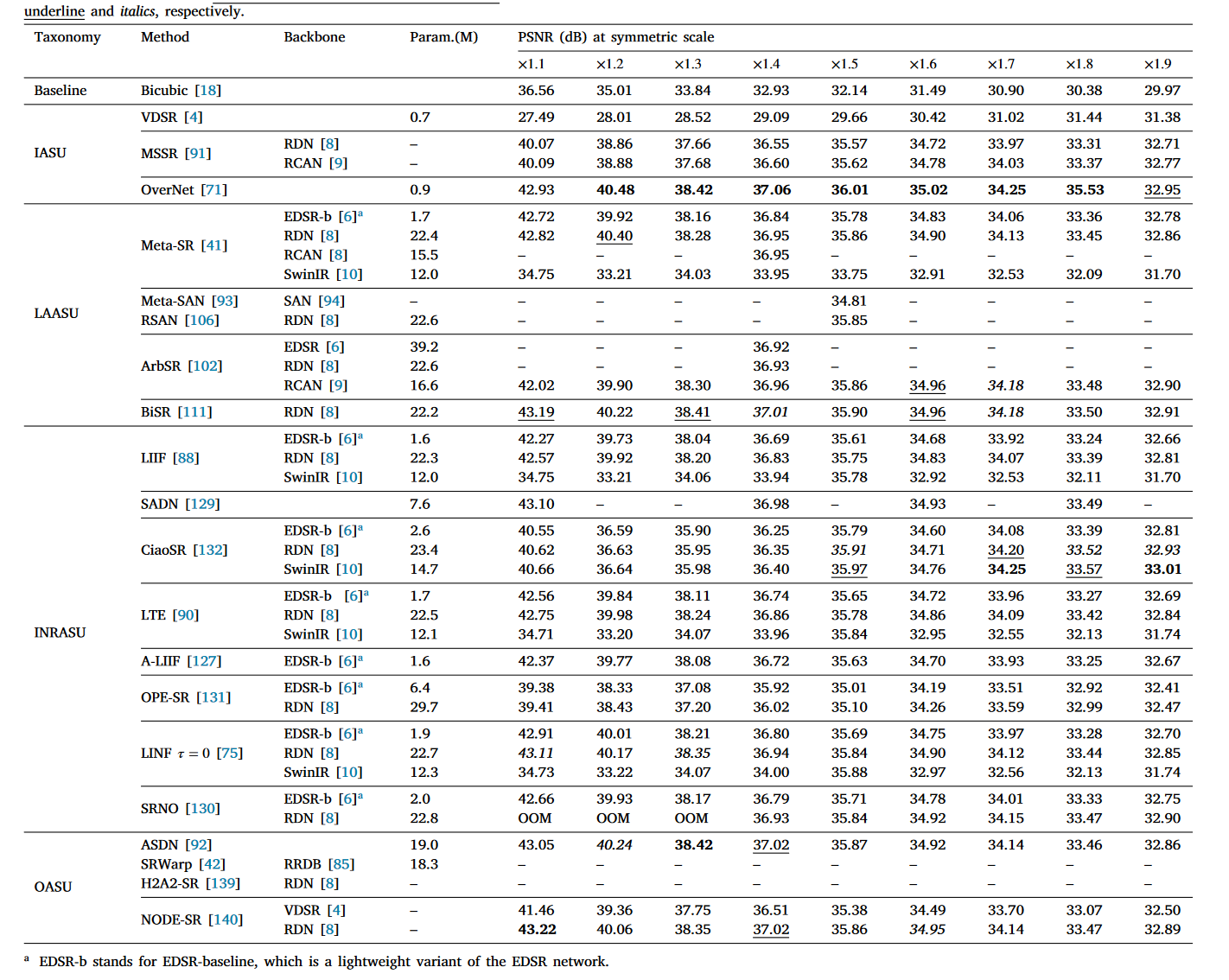
Symmetric non-integer scale:
限制和未来发展
限制
退化模式单一
几乎都是局限于用bicubic插值下采样得到的LR图超分HR图。
整数尺度表现不好
整数尺度上,任意尺度超分效果比不过固定尺度超分网络
慢
又慢又大,没什么好说的,推理能吃满我3090,半天不出一张图。
未来方向
数据
拓展数据类型,不要局限于人工下采样的数据
模型
设计高效且泛化好的模型
应用
拓展到视频,MRI之类的应用


{kind=link}